O princípio filosófico conhecido como “Navalha de Ockham”, formulado no século XIV pelo lógico William de Ockham, estabelece que “entidades não devem ser multiplicadas além do necessário”. Em termos práticos, isso significa que, diante de diferentes explicações possíveis para um mesmo fenômeno, a mais simples tende a ser a mais adequada. Na análise de dados e na modelagem preditiva, essa ideia deixa de ser apenas uma reflexão filosófica e se torna um princípio fundamental para garantir que os modelos apresentem bom desempenho fora do ambiente de treinamento.
À medida que adicionamos complexidade a um modelo preditivo, seja por meio da inclusão de novas variáveis explicativas ou de estruturas mais sofisticadas, o erro dentro da amostra (in-sample) tende a cair continuamente. O modelo se torna progressivamente mais flexível e passa a reproduzir os dados históricos com elevada precisão, criando a impressão de uma solução quase perfeita. Na prática, porém, esse processo frequentemente leva ao chamado overfitting, no qual o algoritmo passa a memorizar ruídos e aleatoriedades sem relevância estrutural.
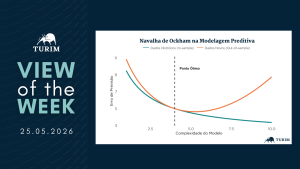
O gráfico desta semana ilustra como o excesso de complexidade pode deteriorar a capacidade preditiva dos modelos. Após determinado ponto, o aumento da complexidade passa a elevar os erros de previsão fora da amostra (out-of-sample), representados pela linha laranja, ainda que os erros nos dados de treinamento, representados pela linha azul, continuem diminuindo.
Aplicar o princípio de Ockham à modelagem significa buscar o ponto de equilíbrio no qual as variáveis relevantes são incorporadas sem que o modelo se torne excessivamente complexo. Em última instância, trata-se de separar o sinal do ruído e priorizar robustez preditiva em detrimento do ajuste excessivo aos dados históricos.